
距离上一篇文章《ChatGPT意味着什么》仅过去了三个月,大模型和AI领域的迅速变化已令人应接不暇,有些趋势日渐清晰了。
大模型之争
GPT-4 有了更强大的推理能力和数据处理能力,并支持插件系统,初现生态端倪。
Anthropic 发布 Claude, 将 context window 提升到 10k token.
Google 发布 PaLM 2 和 Bard 升级,集成 Google Suite。
微软的 Microsoft 365 Copilot 将大模型带进企业办公场景,Windows Copilot 将大模型带进主流电脑操作系统。ChatGPT iOS app 将大模型带进智能手机。
5月23日召开的微软 Build 大会中反复提到的两个概念是 copilot 和 plugin。这两个概念下面我们再详细展开。
大模型厂商同时打造 2C 的聊天产品是一个必然,一来需要展示自己大模型的能力,必须亲自掌控用户和产品的交互;二来需要收集用户反馈以改善自己的大模型;三来可以获取用户流量,2C产品的用户基数越广泛,将来自己的大模型胜出的几率就越高。
大模型厂商的格局大致如下:
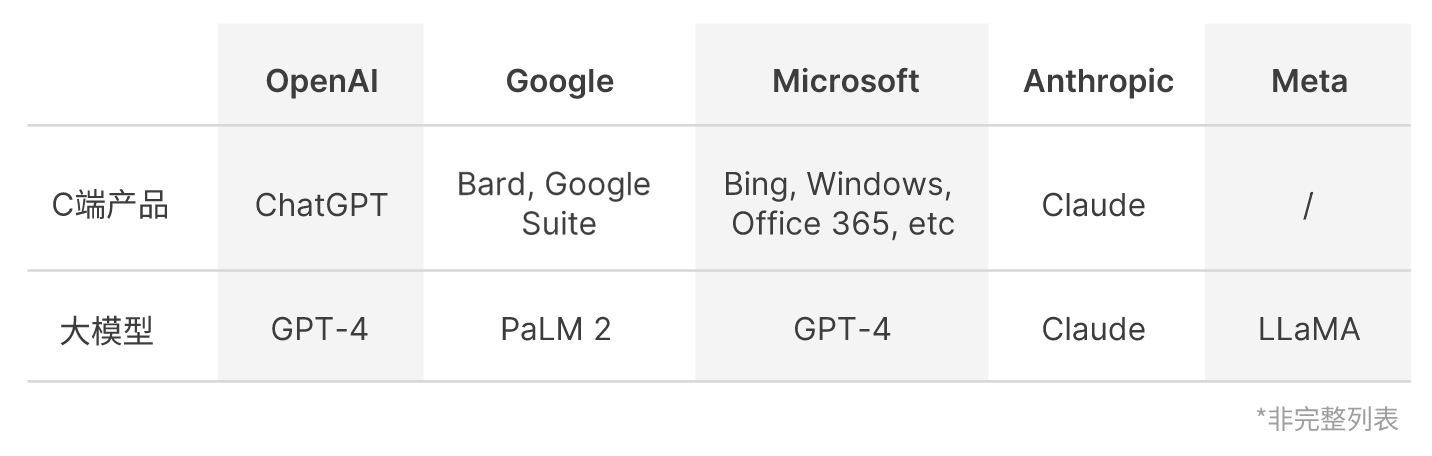
微软没有自己的大模型,它凭借是 OpenAI 的股东,充分利用了 GPT-4 的能力。
Meta 没有 C 端产品,其开源的大模型 LLaMA 更多是被开发者用作 GPT-4 / ChatGPT 的平替。
国内的百度、阿里以及一些创业团队也先后推出了大模型,但是其可用性和性能方面的公开数据还比较少。
交互范式
这波浪潮带来了一个宏观和一个微观的交互范式革新。
Copilot 这个概念是宏观层面的交互范式革新。它本质上是一个记忆力好、聪明、执行力强的「助理」,在数字世界里几乎无所不能。但是,「有事找助理」这种思维方式对大多数人来说都是新的。
举个例子,Windows 操作系统功能强大且复杂,很多用户仅能用到约20%的功能。在没有「助理」之前,用户要想实现目标,必须首先知道「这是可以实现的」,接着上网搜索或在论坛提问,学习「如何实现」,最后亲手操作诸多菜单和按钮来实现。有了「助理」之后,用户只需要提出自己的目标,而且是用自然语言的形式,「助理」就知道行不行、如何做,甚至直接替用户完成操作。
可想而知,Copilot 在许多场景下都能极大提高生产效率,但是这种宏观交互范式的改变需要时间去适应。聊天式交互在操作系统层面的集成,对培养「有事找助理」的思维方式将有很大的促进作用。
聊天式交互则是微观层面的交互范式革新。聊天式交互在大模型出现前就存在了,但是应用并不广泛,最大的制约因素在于「机器人不够聪明」,它们很多时候不能理解人类意图。大模型的出现改变了这一点。大模型非常聪明,能满足甚至超出人类的预期。它的特长是理解自然语言和回复自然语言,这使得大语言模型和聊天式交互几乎是强绑定的。
向聊天式交互的转变会更容易一些。人类对聊天式交互早已习以为常,每天都在和朋友、亲人通过 IM 聊天,跟一个 copilot 聊天也没什么不同。尽管目前有很多写 prompt 的技巧可以对大模型进行「调教」,但我相信随着大模型的成长,会不会写 prompt 对结果的影响不大。
双向集成
制约「助理」能力的诸多因素中,以下两个最为重要: 大模型使用静态数据训练,无法访问实时信息 能做的事局限在「知识领域」和「数字世界」,无法直接和物理世界产生联系
插件 (plugin) 这个概念就是用来增强「助理」能力的。各行各业的软件和互联网企业通过开发插件把自己的服务和「助理」相连,让用户可以通过「助理」来使用服务。这些服务有的擅长访问实时信息(如搜索引擎),有的擅长计算(如 wolfram alpha ),有的擅长和物理世界发生联系(比如电商、出行、旅行等服务),是对大模型能力的完美补充。
大模型厂商通过不断推广自己的 C 端产品,让更多的服务提供商注意到这个新的用户聚集地,并将自己的服务能力「嫁接」给大模型。这与 iOS 和 Android 打造开发者生态的逻辑相同。目前看来这个逻辑很成功,ChatGPT 上线不到一周就吸引了一百万活跃用户,此后也保持了高速增长。而更多的用户也吸引了更多开发者和更多研发投入。
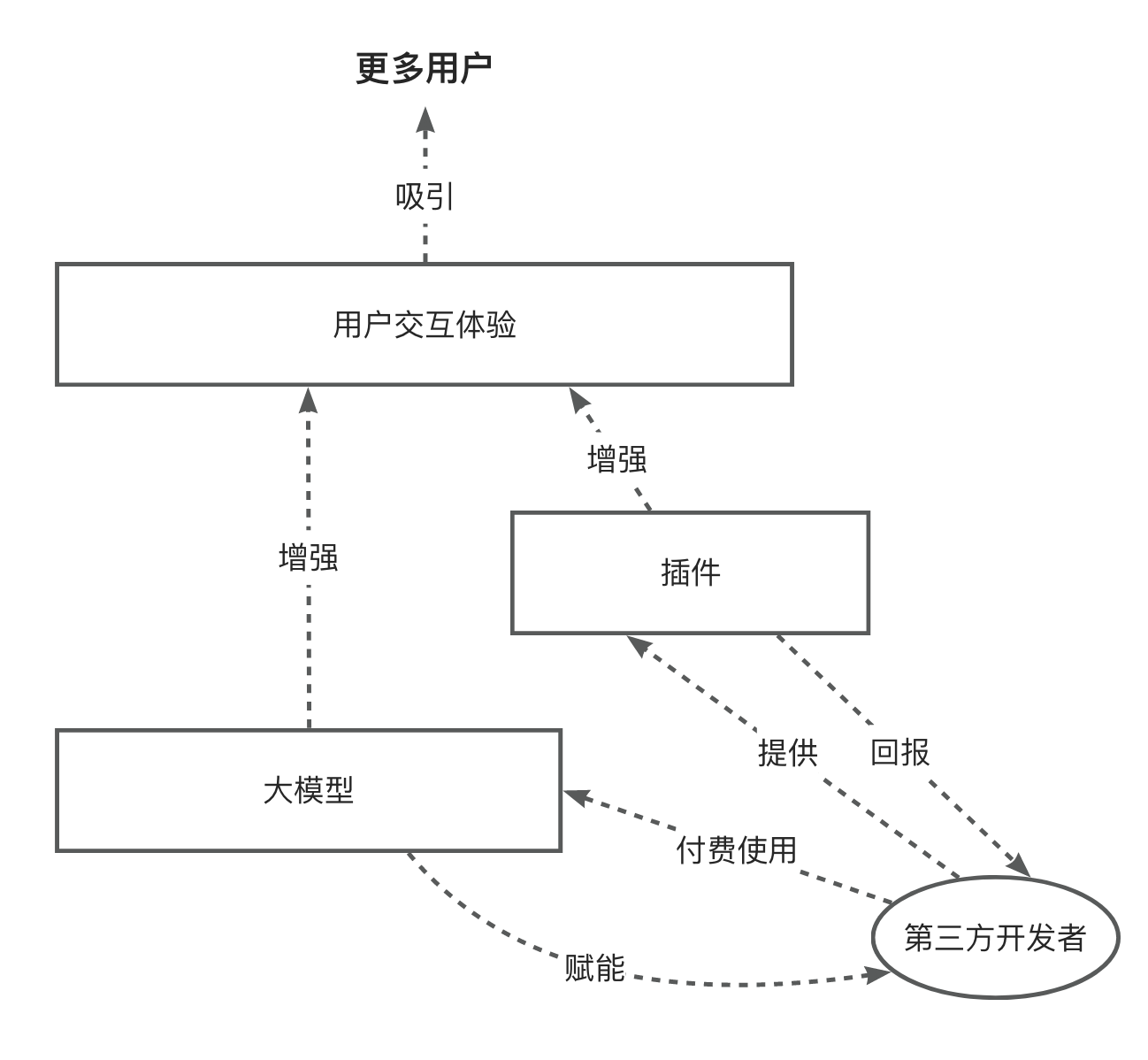
这是从大模型厂商视角来思考的,我们姑且把这种集成模式称作「正向集成」,它解决的问题是「如何让更多的能力为大模型所用」。
用户都在向 ChatGPT 聚集,把自己的服务「嫁接」过去似乎势在必行,就像当年从 web 转向 mobile,后来又出现小程序一样,用户在哪里,店就开到哪里。用户的聚集行为,不仅仅是存量用户的迁移(比如搜索用户转到 ChatGPT 来),也会带来一些增量,比如原来对科技不怎么熟悉的用户也会学着通过聊天式交互去使用数字服务。
从开发者角度看,还可以进行「反向集成」,尝试「让大模型的能力为“我”所用」。这里的“我”可以是初创团队,也可以是已经具备行业地位的企业。例如,我是携程,当用户越来越习惯聊天式交互后,我要不要在自己的平台上提供「聊天订机票」的服务?想要提供,就要将大模型的能力集成到系统里。
但反向集成的必要性存在一定挑战 — 在现有产品中集成聊天式交互不一定能成为企业的竞争优势,反而可能造成「点按式交互」和「聊天式交互」的左右互搏,让用户迷惑。
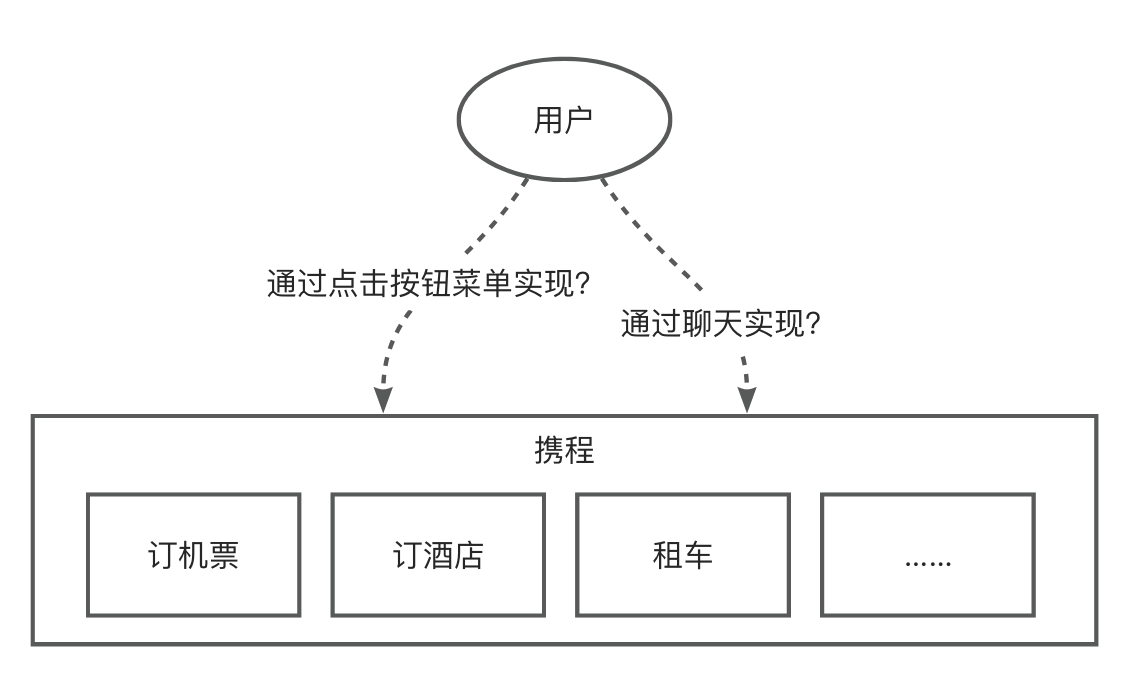
从 OpenAI 网站上看到的大部分成功案例,其企业原本就是提供内容类服务的,甚至交互形式就是聊天式的(比如教育类产品),因此 AI 可以有效提高内容生产效率和智能化程度。而非知识型的产品或服务,尤其是和物理世界联系紧密的,比如出行、电商、零售、地产、银行等行业则暂时没有很好的集成案例。
办公应用
已经被验证了的一类「反向集成」场景是办公应用。
大模型的能力加上企业自身的数据,可以形成企业内部的「超级大脑」和「生产效率神器」— Microsoft 365 Copilot 和 Google Bard + Suite 就是很好的例证。而 Windows Copilot 的出现则更进一步,为个人用户定制了属于自己的「超级大脑」和「生产效率神器」。
无论对个人还是企业来说,这类场景的价值显而易见,但亟待解决的问题是如何保护企业或个人隐私。
虽然微软声称不会使用企业内部数据来训练大模型,但是这种怀疑目前还无法彻底消除。5月,苹果公司因担忧数据泄露,禁止员工使用 ChatGPT 和 Github Copilot 等外部 AI 工具,稍早之前三星、JP摩根、Verzion、Amazon 等公司也采取了类似举措。
结语
大模型技术进步神速,对它的应用还远没有发展的那么快。虽然早有「各行各业都要重做一遍」的说法,但目前行业内并没有掀起这样的热潮。如何利用大模型创造价值,大家都在深入思考和探索。
此外,大模型和AI技术还面临着监管缺失。2023年5月16日,OpenAI 的 CEO Sam Altman 出席美国国会的听证会,接受立法者的质询。Sam 呼吁政府立法加强监管、实施许可证制度、制定安全标准并由第三方专家独立审核 AI 产品的各方面指标。如何设立规则和边界,让这项技术朝着更有利于人类进步的方向发展,政府也在努力思考和探索。
Last but not least, 期待中国的大模型早日赶上。