这段时间网络热议的话题能和《狂飙》拼一拼的,就非 ChatGPT 莫属了。这位无所不能的 AI 机器人在全球掀起了一场狂潮。未来的历史不管是由人类还是由 AI 书写,大概都会认为这是个历史性的时刻。
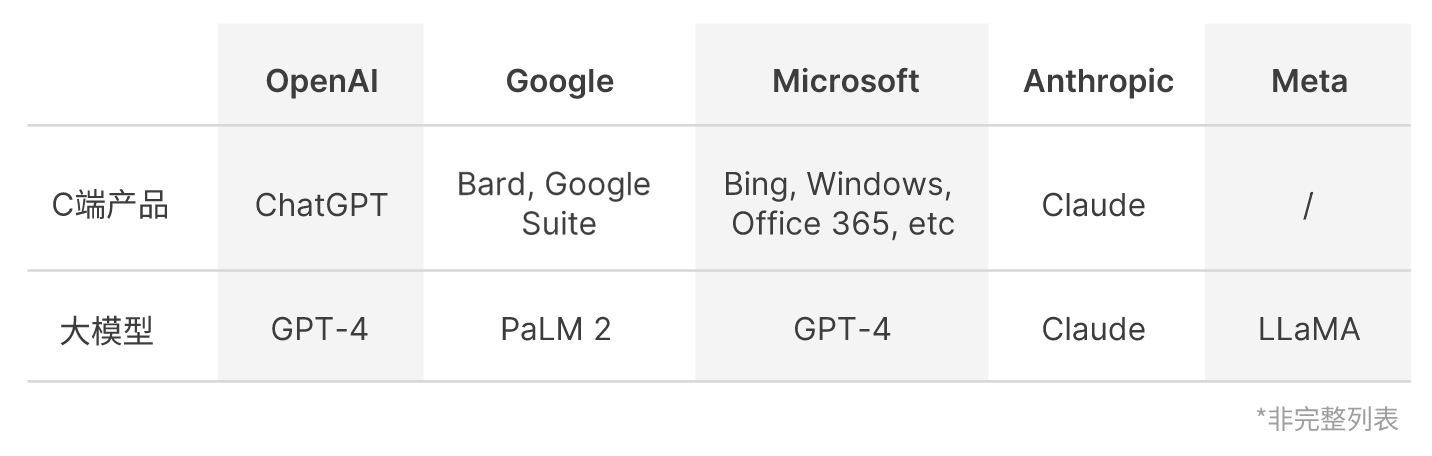
先不说 ChatGPT 能力如何,光是微软和 Google 在这个领域的争夺就赚够了眼球。
微软 vs. Google
ChatGPT 发布于 2022 年 11 月,迅速引发热议,网友纷纷晒出自己和它的对话,并感叹它有多么神奇。
次年1月,微软决定向 ChatGPT 背后的公司 OpenAI 再投资 100 亿美金。微软获取 OpenAI 利润的 75% 直到收回投资,此后仍持有 OpenAI 49% 的股份。之所以说“再投资”,是因为之前已经投过一次了,这个我们后面再说。
看到这股热潮以及微软在这个领域的频繁动作,Google 坐不住了。
2023年2月5日,Google 向 Anthropic 投资 30 亿美金,占其约 10% 的股份。Anthropic 是一家和 OpenAI 类似的从事人工智能研究的公司。实际上,Anthropic 的创始团队就是从 OpenAI 出走的。这家公司曾在 2023 年 1 月推出了类似 ChatGPT 的产品 Claude,但没有受到什么关注。Google 的这项投资被看作是对微软投资 OpenAI 的回应。
Claude 激起的水花和 ChatGPT 明显不在一个量级上。因此 Google 光投资还不够,还要拿出真本事才行。
2月6日,Google 发布了 Google Bard,被认为是 ChatGPT 的有力竞争对手。在发布 Bard 的博文中,Google CEO Sundar Pichai 还不忘提及 GPT 中的 T (Transformer) 是本公司在 2017 年发明出来的,这话听起来酸溜溜的。
Bard 意为“吟游诗人”,尽管这个名字比 ChatGPT 更浪漫,但听着一点都不 AI。
 ▲ 出自 Google Bard 演示视频
▲ 出自 Google Bard 演示视频
微软已然占了先机,当然不能被别人盖过风头。
2月7日,微软召开了一场针对媒体的说明会,活动现场发布了集成 ChatGPT 的 Bing 和 Edge 浏览器。
 ▲ 出自 Bing 演示视频
▲ 出自 Bing 演示视频
微软 CEO Satya Nadella 表示,AI 的发展将在软件领域掀起巨大革命,而首先要触及的领域就是搜索。“在 AI 的帮助下,用户可以从搜索和互联网中获得更多价值”。
轮到 Google 出牌时,Bard 却打了脸。
2月9日,网友发现 Google Bard 在回答一个和韦伯太空望远镜有关的问题时给出了错误的事实(对,就是上面那张 Bard 截图里的内容)。这个消息一出,Google 母公司 Alphabet 股价大跌,市值迅速蒸发了 1000 亿美金。
更有趣的是,媒体的报道口径产生了微妙的变化。

Paul Graham 如此评价:“这就是你不早点发布产品的下场,你的产品总会被人拿来与那些更早发布的产品做比较。(报道里)这个修饰 Bard 的从句对于微软来说比任何新闻都受用。”
要知道 Bing 干了这么多年,在搜索市场占的份额还没超过 3%,就这也已经是排行老二了。在搜索领域从来没正眼瞧过别人的 Google 现在被人拿来与 Bing 做比较,真是伤害性不大但侮辱性极强。
让我们假设 Bing 能最终取得对 Google 的胜利,这场胜利一定不会是以 Bing 一路蚕食 Google 的搜索市场份额为代表的,而是 Bing 创造出一种全新的从互联网上获取信息的方式,以及与之配套的行业生态。
看热闹归看热闹,考虑到训练大语言模型需要的技术、数据、资金、算力、时间等资源,除这两家之外,也许没有其他玩家有实力进场了。
唯一的变量是中国。因为各种非技术因素,我国显然不会基于 OpenAI 或 Google 的模型进行应用开发。未来中国也许会出现类似的 AI 技术基础设施,我们拭目以待。
不管玩家间争斗结果如何,这个新技术时代的大门,已然开启。
AIGC (AI Generated Content, AI 生成内容)
见识过 ChatGPT 的能力后,网友感叹:还有什么是 AI 不能做的?
ChatGPT 是一个 text to text 模型,尽管其底层的模型非常复杂,训练数据量十分巨大,但简单的说,这个模型的工作原理是:输入一段文字,输出一段文字作为回应。
AI 模型除了能输出文字,还能输出别的吗?答案是肯定的。
以 OpenAI API 为例,它提供三个 AI 模型供开发者使用:
- GPT-3:自然语言 → 自然语言
- Codex:自然语言 → 程序设计代码
- DALL·E:自然语言 → 图像
代码:Copilot
 ▲ 出自 Github Copilot 官网
▲ 出自 Github Copilot 官网
早在2021年10月,Github 便在 JetBrains 市场上以 IDE 插件形式发布了 Copilot. Github 将 Copilot 定义为”你的AI编程助手”,它可以实时地在编辑器里生成语句和完整函数代码。
Copilot 基于 OpenAI Codex 打造,是微软投资 OpenAI 十亿美金结出的第一个成果。这个十亿美金,就是我们前文提到的微软对 OpenAI 的第一次投资。
2022年3月,Copilot 在 Visual Studio 上发布,目前已集成到各大主流 IDE 中,包括 Visual Studio, NeoVim, VS Code, JetBrains IDE 等,已经成为一个商业产品。
图像:DALL·E 2 和 Stable Diffusion 2.0
AI 生成图像在 ChatGPT 流行起来之前就已经引发不少关注了,但相比聊天,有心思用 AI 搞“艺术创作”的人本来就少,而且能找到合适的文字提示让 AI 画出赏心悦目的画也有一定门槛,因此它没能像 ChatGPT 这样成为全球大流行现象。
这个领域的主要产品是来自 OpenAI 的 DALL·E 2 和来自 stability.ai 的 Stable Diffusion 2.0. 两者发布时间差不多,前者是2022年7月,后者是2022年11月。他们的使用方法几乎一样,连商业化的方式也类似。
 ▲ DALL·E 2 生成的图片
▲ DALL·E 2 生成的图片
stability.ai 这家公司2020年在英国伦敦成立,2022年10月获得了约一亿美金投资,公司估值约为十亿美金。它的主要产品就是开源的模型 Stable Diffusion 2.0 和基于它进行图形绘制的工具软件 DreamStudio。
 ▲ Stable Diffusion 2.0 生成的图片
▲ Stable Diffusion 2.0 生成的图片
音乐:MusicLM
2023年1月,Google 发表了一篇名为 MusicLM: Generating Music From Text 的论文,声称已经攻克了从文字生成高品质音乐的 AI 模型,同时在 Github 上发布了一些示例。
这个消息也没有引起 ChatGPT 那样的波澜。我想一方面是因为它还没有公开可用的产品,另一方面,对音乐感兴趣的人也远没有对聊天感兴趣的人多。
下面这段音乐,就是根据如下文字描述生成的:
The main soundtrack of an arcade game. It is fast-paced and upbeat, with a catchy electric guitar riff. The music is repetitive and easy to remember, but with unexpected sounds, like cymbal crashes or drum rolls.
https://general-1258275882.cos.ap-chengdu.myqcloud.com/chatgpt/audio.mp3
除此之外,还有一些公司在垂直领域打造 AIGC 的产品。例如,Galileo.ai 号称借助 GPT-3 的能力实现了从文字描述生成 UI 设计。从它的演示视频来看,似乎并不比直接在 Mobbin 或者 Pinterest 上搜索图片进行参考来得更方便。但是,如果它生成的设计文档真能直接用 Figma 编辑,还是会极大提高设计师的生产力。
我会被 AI 取代吗
前几天有新闻报道 ChatGPT 通过了 Google 公司三级工程师的编程面试,这一级别工程师在 Google 可以拿到 18.3 万美金年薪。
网友不停测试 ChatGPT,发现它什么都能答上来,写个文章、拟个合同、作诗、写对联都不在话下,许多人开始担心自己将被 AI 取代。
人类历史上每次技术革命都会消灭一些工作岗位,但是人类并没有就此躺平,而是利用新技术创造出新的工作岗位,把人类文明提升到更高的高度 – “君子生非异也,善假于物也”。
ChatGPT 也一定会消灭一些岗位,但人类也会想出办法更好地利用这些工具。未来的我们不论从事什么行业,都能以 AI 生成的内容作为草稿,谁说这不是对生产力的解放呢?
目前的 AI 模型在能力上还有许多不足,训练成本过于高昂,在道德、法律方面还需要更多的监管,但是它向前的步伐已经不会停下了,它会催生一个新的技术时代。
思考这个问题有两个视角:技术从业者和普通人。
技术从业者想的是“技术革命”,是构建新时代的样貌,预测并推动行业变迁,并从中占据一席之地。
上文提到的 Galileo.ai 这样的公司,未来会大量涌现,把 ChatGPT 相关的技术与各个行业进行交叉和创新。事实上,从 OpenAI API 网站上的例子来看,已经有上千家公司借助 GPT-3 的能力开发出自己的产品了。这些产品能够帮人更好的学习语言、报税、分析客户反馈等。
这些创新自然会消灭掉一些行业,也会催生出新的行业,一如当年互联网和移动互联网所做的那样。
王建硕说:“有和没有,是质变;而质变,会引发与之相关的产业的产生,而这个产业已经和它本身没啥关系了。解释一下:浏览器的诞生之日,几乎就是互联网产业诞生之日;而互联网产业,绝不是浏览器产业;ChatGPT 的大模型诞生之日,就是基于自然语言的人机交互时代的诞生,而这个时代绝不是大语言模型时代。催生了一个时代的技术,不见得是这个时代最重要的技术。”
对于普通人(比如记者、律师等),努力跟上潮流,关注技术的发展,思考新技术对于自己行业的影响,找到未来图景里 AI 无法替代的价值,学习那些技能,或者转行。
以上思考的出发点是把 AI 和机器智能当作是为我所用的工具,目标是推动人类社会进步。但是,这是机器想要的吗?如果有一天,“机器智能弱于人类智能”这个大前提崩塌,又会怎么样?
鲍捷认为人类社会终将被机器智能取代,他在《脱碳入硅》里说:“人类担心工作职位被机器取代是自大的。实际上,机器将消灭社会的需求,而不是满足这些需求本身。正如机器已经帮助我们基本消灭了对狩猎和萨满的需求,未来也将消灭对律师和教师的需求。因为我们并不重要。”
人类智能 vs. 机器智能
人类该如何与机器共存的问题,已经在许多文学影视作品中被一再探讨了。经典如《黑客帝国》向我们描述了一种可能 — 人类无法正确处理与机器的关系,也无法克服人性的弱点,造成了“被机器豢养”的结果。理性来看,这当然不是我们想要的局面,但是在机器制造出来的“真实的欢愉“面前,又有多少人能抵挡诱惑。实际上,AI 根本不会为人类创造 Matrix 保留个体意识,这太不划算了。
我们目前面临的是机器在微观层面上对人类的超越 — 从拥有的知识量来看,ChatGPT 可能已经超过了所有人。然而这种个体层面的比较并没有太大意义,机器智能的优势是群体性和社会性的。机器智能对人类社会的全面接管,才是不可逆转的大势。
《脱碳入硅》里提到:“关于人类被机器取代,我们要明确不是‘人’被机器人取代,而是‘人类社会’被‘社会机器’取代。人可能依然有一部分存在,但是是作为社会机器的线粒体,用文化上已经是服从机器进化的需要,而不是人本身繁衍的需要。从文化的意义上,人类这时候已经亡了…… 我们的意识是无足轻重的,意识只是进化长河里偶尔出现的小浪花。”
电影《银翼杀手》里被猎杀的对象是内里机器外表人形的复制人,这依然是人类根据自己的形象构建的假想敌。罗伊·贝蒂死前对着追捕他的银翼杀手德卡德说出的那段经典台词,像极了机器送给人类的挽歌:
我见过的光景,你们人类绝对无法想象。
攻击舰在猎户座的边沿熊熊燃烧,
我曾见 C 射束,
在唐怀瑟之门近旁的黑暗中灿灿生辉。
所有这些瞬间都会在时光长河中湮没,
如同……雨中的……泪水。
死时已到。
人类文明终会延续,但也许是以一种我们意想不到的形式。
参考资料
- Google is investing $300M in an OpenAI challenger that will take on ChatGPT while focusing on A.I. safety.
- An important next step on our AI journey.
- Reinventing search with a new AI-powered Microsoft Bing and Edge, your copilot for the web.
- Google shares drop $100 billion after its new AI chatbot makes a mistake.
- MusicLM: Generating Music From Text.
- MusicLM examples.
- ChatGPT Passes Google Coding Interview for Level 3 Engineer With $183K Salary.
- ChatGPT 开启了一个时代,但与之竞争已成为局部战争。
- 脱碳入硅。